
21-底层程序设计
底层程序设计
A good system can’t have a weak command language. [^1]
目录
[TOC]
底层程序设计
零 前言
有些程序需要进行位级别的操作。位操作和其他一些底层运算在编写系统程序(包括编译器和操作系统),加密程序,图形程序以及一些其他需要高执行速度或高效利用空间的程序非常有用。
一 位运算符
C 语言提供了 6 个位运算符。
关于位运算符参考文章:https://mp.weixin.qq.com/s/rWFUortJu0JAw1kIwSegRQ
1. 移位运算符
<<左移位
>>右移位
操作数可以为任意整数类型(包括 char型)。对两个操作数都会进行整数提升,返回值的类型是左操作数提升后的类型。
i << j将 i 中的位左移 j 位后的结果。每次从 i 最左端溢出一位,在 i 的最右端补 0i >> j将 i 中的位右移 j 位后的结果。每次从 i 的最右端溢出一位。如果 i 是无符号数或非负值,在 i 左端补 0;如果 i 是 负值,其结果是由实现定义的:一些实现会在左端补 0,其他实现会在保留符号位而补 1 。
**可移植性技巧:**仅对无符号数进行位运算。
例:
unsigned short i, j; |
如上面所示,两个运算符都不会改变他它的操作数。如果想要改变:
i <<= 2; |
位移运算符的优先级比算数运算符的优先级低,所以:
i << 2 + 1; |
等价于:
i << (2 + 1); |
而不是:
(i << 2) + 1; |
2. 其他位运算符
~按位求反
&按位与
|按位或
^按位异或
~是一元运算符,对操作数进行整数提升;其他是二元运算符,对操作数进行常用的算术转换。
它们对操作数的每一位进行布尔运算。
注意:不要混淆 & 与&&, |与 ||,它们绝不相同。
例:
unsigned short i, j, k; |
其中对 ~i 是基于 unsigned short 类型的值占有 16 位的假设。
运算符可以帮助我们使底层程序的可移植性更好。比如我们需要一个整数,它的所有位都为 1,写成~0;如果我们需要一个整数,除了最后 5 位其他位数都为 1,写成~0x1f
优先级:
最高 ~ |
复合赋值运算符:
i &= j; |
3. 用位运算符访问位
unsigned short i; |
-
位的设置。假设我们需要设置 i 的第 4 位(我们假定最高有效位为第15位,最低有效位为 0 位。)。将 i 的值与 0x0010(一个在第 4 位上为 1 的“掩码”)进行或运算:
i = 0x0000; // i is now 0000 0000 0000 0000
i |= 0x0010;// i is now 0000 0000 0000 1000如果需要设置的位存储在 j 中,可以用移位运算符构造掩码:
i |= 1 << j;// sets bit j
如果 j 的值为 3,
1 << j是 0x0008 -
位的清除。要清除 i 的第 4 位,可以使用第 4 位为 0 ,其他位为 1 的掩码:
i = 0x00ff; // i is now 0000 0000 1111 1111
i &= ~0x0010; // i is now 0000 0000 1110 1111按照相同的思路,得出惯用法:
i &= ~(1 << j);//clear bit j
-
位的测试。下面的 if 语句测试 i 的第4位是否被设置:
if(i & 0x0010) ...
测试第 j 位是否被设置,使用惯用法:
if(i & 1 << j) ...
为了使位的操作更容易,经常会给他们起名字,给第 0,1,2 位定义名字:
设置,清除或测试 BLUE 可以如下进行:
i |= BLUE; |
同时对几个位操作也一样简单:
i |= (BLUE | GREEN); |
if 语句测试 BLUE 位或 GREEN 位是否被设置了。
4. 用位运算符访问位域
处理一组连续的位(位域)比处理单个位要复杂一点。下面是两种最常见的位域操作的例子。
-
修改位域。修改位域需要先使用按位与(清除位域),再使用按位或(存入位域)。
将二进制的 101 存入 i 的 4~6 位:
i = i & ~0x0070 | 0x0050;
注意:使用
i |= 0x0050并不总是可行,这只会设置第 6 位和第 4 位,但是不会改变第 5 位。假设 j 包含了需要存储到 i 的第 4 位到第 6 位的值。我们需要在执行按位或操作之前将 j 移位至相应的位置:
i = i & ~0x0070 | j << 4;
因为
<<优先级高于|,我们可以省略括号(加上也没问题)。 -
获取位域。当位域处在数的最右端(最低有效位)时,获取它十分简单。例如,获取变量 i 的第 0~2 位:
j = i & 0x0007;
如果位域不在 i 的右端,那么需要先将位域移位至右端,在使用 & 提取位域。例如,获取 i 的第 4~6 位:
j = (i >> 4) & 0x0007;
程序:XOR 加密
对数据加密的一种最简单的方法就是,将每个字符与一个密钥进行异或(XOR)运算。假设密钥时一个 & 字符。如果将它与字符 z 异或,我们会得到 \ 字符(假定字符集为 ACSII 字符集)。具体计算如下:
00100110 (& 的 ASCII 码) |
要将消息解密,只需要采用相同的算法。例如,如果将 & 与 \ 异或就可以得到 &:
00100110 (& 的 ASCII 码) |
下面的程序 xor.c 通过每个字符于 & 字符进行异或来加密消息。原始消息可以由用户输入也可以输入重定向从文件读入。加密后的消息可以在屏幕上显示也可以通过输出重定向存入到文件中。例如 msg 文件包含以下内容:
If two people write exactly the same program, each should be put in |
为了对文件 msg 加密并将加密后的消息存入文件 newmsg 中,输入以下命令:
xor <msg >newmsg |
文件 newmsg 将包含下面的内容:
o@ RQI VCIVJC QTORC C^GERJ_ RNC UGKC VTIATGK, CGEN UNISJB DC VSR OH |
要恢复原始消息,需要命令:
xor <newmsg |
将原始消息显示在屏幕上。
正如例子中看到的那样,程序不会改变一些字符,包括数字。将这些字符于 & 异或会产生不可见的控制字符,这在一些操作系统中会引发问题。在这里,为了安全起见,我们使用 isprint函数来确保原始字符和新字符都是可打印字符(即不是控制字符)。如果不满足,让程序写原始字符,而不是新字符。
xor.c
|
二 结构中的位域
声明其成员表示位域的结构。
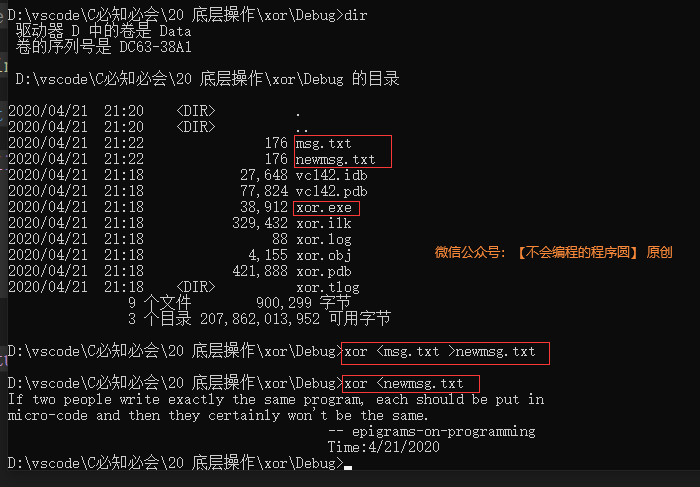
例如,我们来看看 MS-DOS 操作系统(通常简称 DOS)是如何存储文件的创建和最后修改日期的。由于日期,月和年都是很小的数,将它们按整数存储会浪费空间。DOS 只为日期分配了 16 位,5 位用于日,4 位用于 月,7 位用于年。
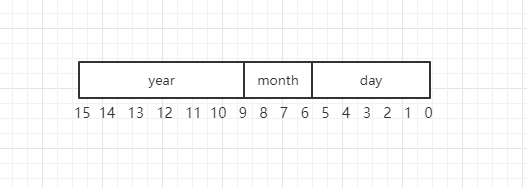
利用位域,我们可以定义相同形式的 C 结构:
struct file_data{ |
每个成员后面指定了它所含用的长度。因为所有成员类型一样,我们可以简化声明:
struct file_data{ |
位域的类型必须是int, unsigned int, signed int。使用 int 会引发二义性,因为一些编译器将位域的最高位作为符号位,而其他一些编译器不会。
可移植性技巧:将所有的位域声明为:unsigned int或signed int
C99 中,位域也可以具有类型_Bool。
我们可以将位域像结构的其他成员一样使用:
struct file_data fd; |
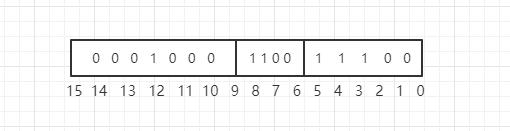
注意:year 成员相对于 1980 年(根据微软的描述,这是 DOS 出现的时间)存储的。在这些赋值语句之后,变量 fd 的形式如下所示:
使用位运算可以达到同样的效果,使用位运算甚至可以更快。但是,让程序更易度通常比节省几微妙更重要一些。
通常意义上讲,位域没有地址,C 语言不允许讲 & 运算符用于位域。由于这条规则的限制,像 scanf 这样的函数无法直接向位域中存储数据:
scanf("%d", &fd.day);// wrong |
1. 位域是如何存储的
C 标准在如何存储位域方面给编译器保留了相当的自由度。
“存储单元”的大小是由实现定义的,通常为 8 位,16 位或 32 位。当编译器处理结构的声明时,会将位域逐个放入存储单元,位域之间没有空隙,直到剩下的空间不够存放下一个位域了。这时,一些编译器会跳到下一个存储单元的开始,而另一些则会将位域拆开夸存储单元存放。位域存放的顺序(从左至右,还是从右至左)也是由实现定义的。
前面的 file_data 例子假设存储单元是 16 位长的。我们也假设位域是从右向左存储的。(第一个位域占据低序号位)
C 语言允许省略位域的名字。未命名的位域经常作为字段之间的“填充”,以保证其他位于存储在适当的位置。考虑与 DOS 文件关联的时间,存储方式如下:
struct file_time{ |
你可能会奇怪将秒 —— 0 ~ 59 之间的数存放在一个 5 位字段中呢。实际上,DOS 将描述除以 2,因此 seconds 成员实际存储的是 0 ~ 29 的数。如果我们不关心 seconds 字段,可以不给它命名:
struct file_time{ |
其他位域仍会正常对齐。
另一个用来控制位于存储的技巧是指明未命名字段长度为 0:
struct s{ |
长度为 0 的位域是给编译器的一个信号,告诉编译器将下一个位域在一个存储单元的起始位置对齐。假设存储单元是 8 位长的,编译器会给成员 a 分配 4 位,接着跳过余下的 4 位到下一个存储单元,然后给成员 b 分配 8 位。如果存储单元是 16 位,则会在 a 分配 4 位后跳过余下的 12 位分配 b。
三 其他底层技术
1. 定义依赖机器的类型
依据定义,char 类型占据一个字节,所以我们有时当字符是字节,并用它们存储一些并不一定是字符形式的数据。但这时候最好定义一个 BYTE 类型:
typedef unsigned char BYTE; |
x86 体系结构大量使用了 16 位的字,我们可以定义:
typedef unsigned short WORD; |
2. 用联合提供数据多个视角
在 C 语言中,联合经常被用于从两个或更多的角度看代内存块。
前面我们知道 file_date 结构正好可以放入两个字节,我们可以将任何两个字节的数据当作是一个 file_date 结构。下面定义一个联合可以使我们很方便的将一个短整数与文件日期相互转换:
union int_date{ |
通过这个联合,我们可以以两个字节的形式获取磁盘文件中的日期,然后提取出其中的 month, day, year 字段的值。相反的,我们可以以 file_date 结构构造一个日期,然后作为两个字节写入磁盘中。例如:
void print_date(unsigned short n){ |
x86 处理器包含 16 位寄存器 ——AX,BX,CX 和 DX 。每一个寄存器都可以看作是两个 8 位的寄存器。例如,AX 可以被划分为 AH 和 AL 两个寄存器。
当针对于 x86 的计算机编写底层程序时,可能会用到寄存器中的值的变量。我们需要对 16 位寄存器和 8 位寄存器进行访问,同时要考虑到它们之间的关系(改变 AX 会改变 AH 和 AL;反之同理)。所以我们可以构造一个联合包含两个结构(分别存储 16 位和 8 位的寄存器):
union { |
下面时是一个使用 regs 联合的例子:
regs.byte.ah = 0x12; |
输出:
AX: 1234 |
注意,尽管 AL 寄存器是 AX 寄存器的“低位”部分而 AH 是“高位”部分,但在 byte 结构中 al 在 ah 之前。原因是,当数据项多于一个字节时,在内存中有两种存储方式:大端(big-endian) 和 小端(small-endian) 。小端代表:低位内存(al 是最低位)存储数的低位(34 是低位),大端则相反(可以记小端为:小小小)。C 对存储的的顺序没有要求,因为这取决于程序执行时所使用的 CPU。x86 处理器假设数据按小段方式存储。
在底层对内存进行操作的程序必须注意字节的存储顺序。处理含有非字符数据的文件时也要当心字节的存储顺序。
3. 将指针作为地址使用
指针实际上就是一种内存地址。地址所包含的位的个数与整数(或长整数)一致。构造一个指针来表示某个特定的地址是十分方便的:只需要将整数强转为指针就行。比如,将地址 1000 存入一个指针变量:
BYTE* p; |
程序:查看内存单元
这个程序允许用户查看计算机内存段,这主要得益于 C 允许把整数用作指针。大多数 CPU 执行程序时都是处于“保护模式”,这就意味着程序只能访问那些分配给它的内存。这种方式还可以阻止对其他应用程序和操作系统本身所占用的内存的访问。因此我们只能看到程序本身分配到的内存,如果要对其他内存地址进行访问将导致程序崩溃。
程序 veiw_memory.c 先显示了该程序主函数和主函数中第一个变量的地址,这样可以给用户一个线索去了解那个内存可以被探测。程序接下来提示用户输入地址(16 进制格式)和需要查看的字节数,然后从指定地址开始显示指定字节内存块的内容。
字节按 10 个一组的方式显示(最后一组可能达不到 10 个)。每组字节的首地址显示在一行的开头,然后是该组的字节(16 进制格式),再后面为该组字节的字符显示。只有打印字符(使用 isprint函数判断)会被显示,其余的被显示为 .。
假设 int 类型大小为 32 位,地址也是 32 位长。
格式如下:
Address of main function: 5712bc |
.
Address of main function: 5712bc |
(前 4 个字节是我们输入的表示地址的整数,注意它的每个字节存储顺序)
view_memory.c
|
4. volatile类型限定符
在一些计算机中,一部分内存空间是“易变”的,保存在这些内存空间的值可能在程序运行期间发生改变,即使程序自身并未试图存放新值。例如,一些内存空间可能被用于保存直接来自输入设备的数据。
volatile类型限定符使我们可以通知编译器,程序中的某些数据是“易变”的。所以,它常用于声明指向易变空间的指针:
volatile BYTE* p; |
为了了解为什么需要使用 volatile ,我们假设指针 p 指向的内存空间用于存放用户通过键盘输入的最近一个字符。这个空间是易变的:用户每输入一个新字符,这里的值都会发生改变。我们可能通过下面的循环获取键盘输入的字符,并将它们存储到一个缓冲区中:
while(缓冲区未满){ |
比较好的编译器可能会注意到这个循环没有改变 p,也没有改变 *p,因此编译器可能会对程序进行优化,使 *p 只被取一次:
在寄存器中存储 *p; |
优化后的程序会不断重复复制同一个字符到缓冲区中,这不是我们期望的。需要将 p 声明为 volatile 类型可以避免这种问题。
[^1]: 好系统无坏指令。Epigrams on Programming 编程警句
参考资料:《C语言程序设计:现代方法》